データソースは、厚生労働省発表のPDFデータを用います。
2020年3月20日時点のURLから
https://www.mhlw.go.jp/stf/newpage_10204.html
国内事例(チャーター便、クルーズ船の患者を除く)における都道府県別
患者報告数(2020年3月15日12時時点)
のPDFを利用することとします。
PDFの読み込み¶
データ取得部分は今回は割愛します。
PDFデータの読み込みにはpdfminerを使用します。
from pdfminer.pdfinterp import PDFResourceManager
from pdfminer.pdfinterp import PDFPageInterpreter
from pdfminer.converter import TextConverter
from pdfminer.layout import LAParams
from pdfminer.pdfpage import PDFPage
from io import StringIO
def convert_pdf_to_txt(path):
rsrcmgr = PDFResourceManager()
retstr = StringIO()
laparams = LAParams()
laparams.detect_vertical = True
device = TextConverter(rsrcmgr, retstr, laparams=laparams)
fp = open(path, 'rb')
interpreter = PDFPageInterpreter(rsrcmgr, device)
maxpages = 1
caching = True
pdf_text = ''
for page in PDFPage.get_pages(fp, None,
maxpages=maxpages,caching=caching,
check_extractable=True):
interpreter.process_page(page)
str2 = retstr.getvalue()
pdf_text += str2
fp.close() device.close() retstr.close() return pdf_text
result_list = []
result_txt = convert_pdf_to_txt('000608453.pdf')Japanmapへ読み込むための加工
Japanmapへ読み込ませるために、データを辞書型へ変換し
人数のデータを整数へ加工します。
lines = result_txt.split('\n')
data = {}
for i,line in enumerate(lines[4:],start=0):
if line and ('道' in line or '県' in line or '府' in line or '都' in line ):
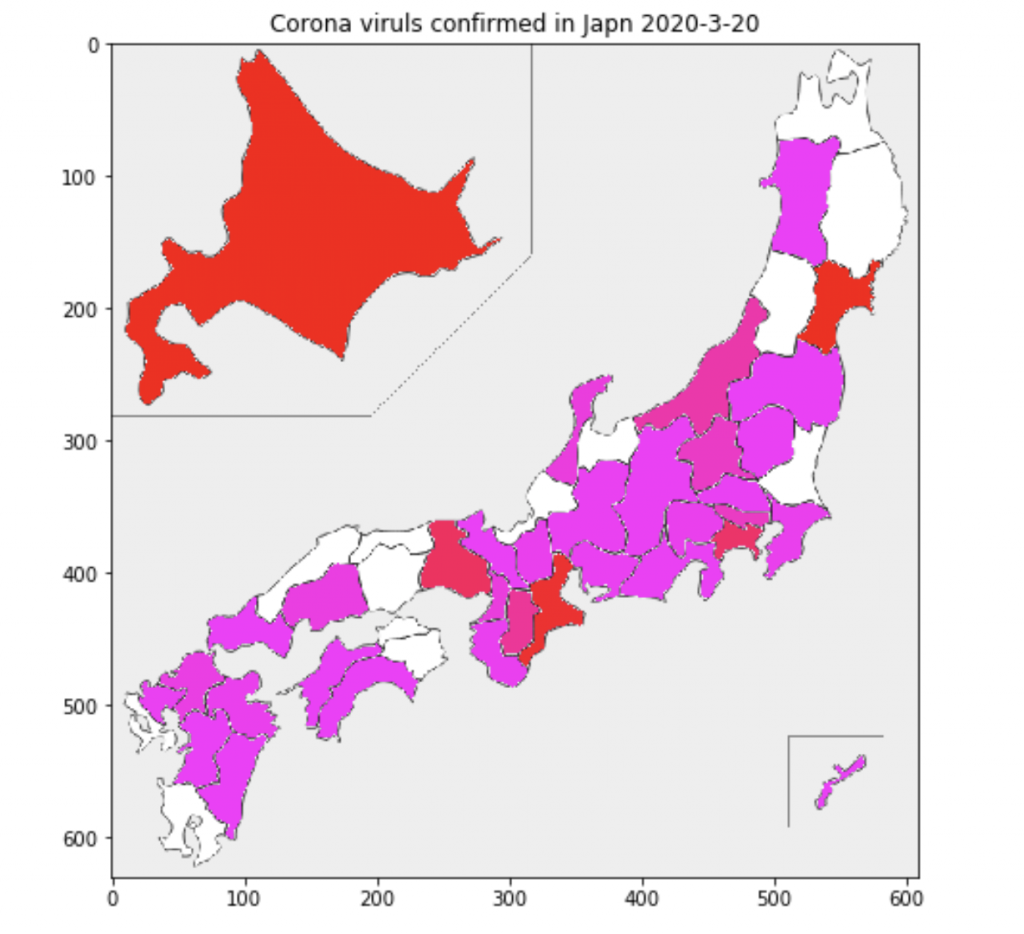
data[line.strip()] = int(lines[4+37+(2*(i))].split(' ')[0])色の調整
数値データをカラーデータへ変換します。
m = max(data.values())
def color_scale(r):
return (255,0,int(255 - 255/m * r*5))
for p,d in data.items():
c = color_scale(d)
data[p] = c描画
%matplotlib inline
import japanmap
import matplotlib.pyplot as plt
rcParams['figure.figsize'] = 8,8
plt.imshow(picture(data));
plt.title('Corona viruls confirmed in Japn 2020-3-20')